切换主题
快速入门
应用介绍
LightCC平台目前已经上线的应用如下表所示,更多热门应用正在上新中,敬请期待。
应用会不断更新,可能随时更新,请以网站实际上线的应用为准,下表仅供参考。
| 应用名称 | 应用简介 | 备注说明 |
|---|---|---|
| Stable Diffusion WebUI | 预制部分模型、loRA和插件 | SD v1.9版本 |
| ComfyUI 官方版 | 基于节点流程的 SD,精准的工作流定制和完善的可复现性 | 自带网络加速 |
| Stable Diffusion XL | 模型和插件均预制好 XL 版本 | SD XL 版本 |
| Jupyter | AI 开发环境,内置 Anaconda、Tensorflow、Torch 等 | |
| ChatTTS | ||
| Web SSH | 高级 AI 开发环境,内置 Anaconda、Tensorflow、Torch 等 | |
| SSH | 完整版终端模拟器,可以兼容自定义模型 |
新建应用
登录“LightCC平台”
以“Stable Diffusion官方版”为例
点击应用中心
点击左侧导航栏“应用中心”选择Stable Diffusion 官方版
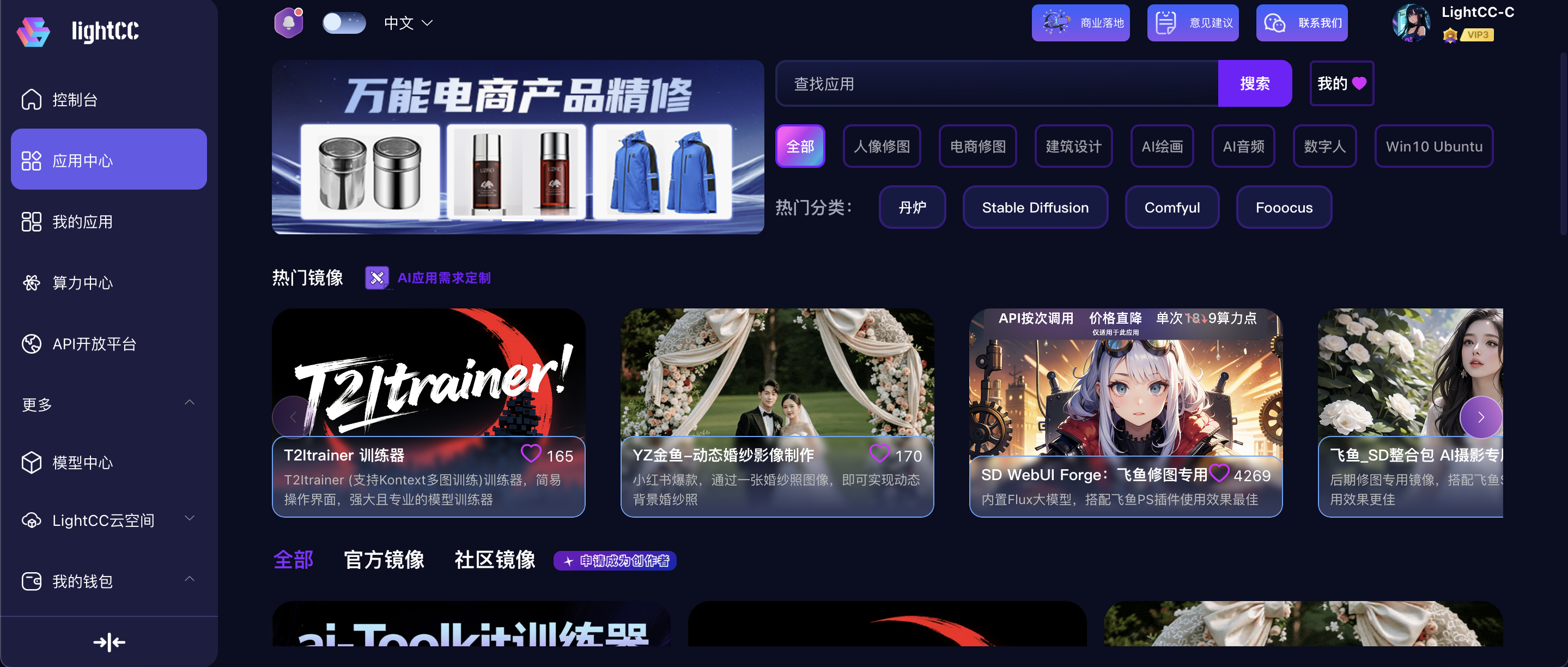
选择配置
选择GPU方式/数量/型号/计费方式
图片介绍点击“创建应用”会进入我的应用页面
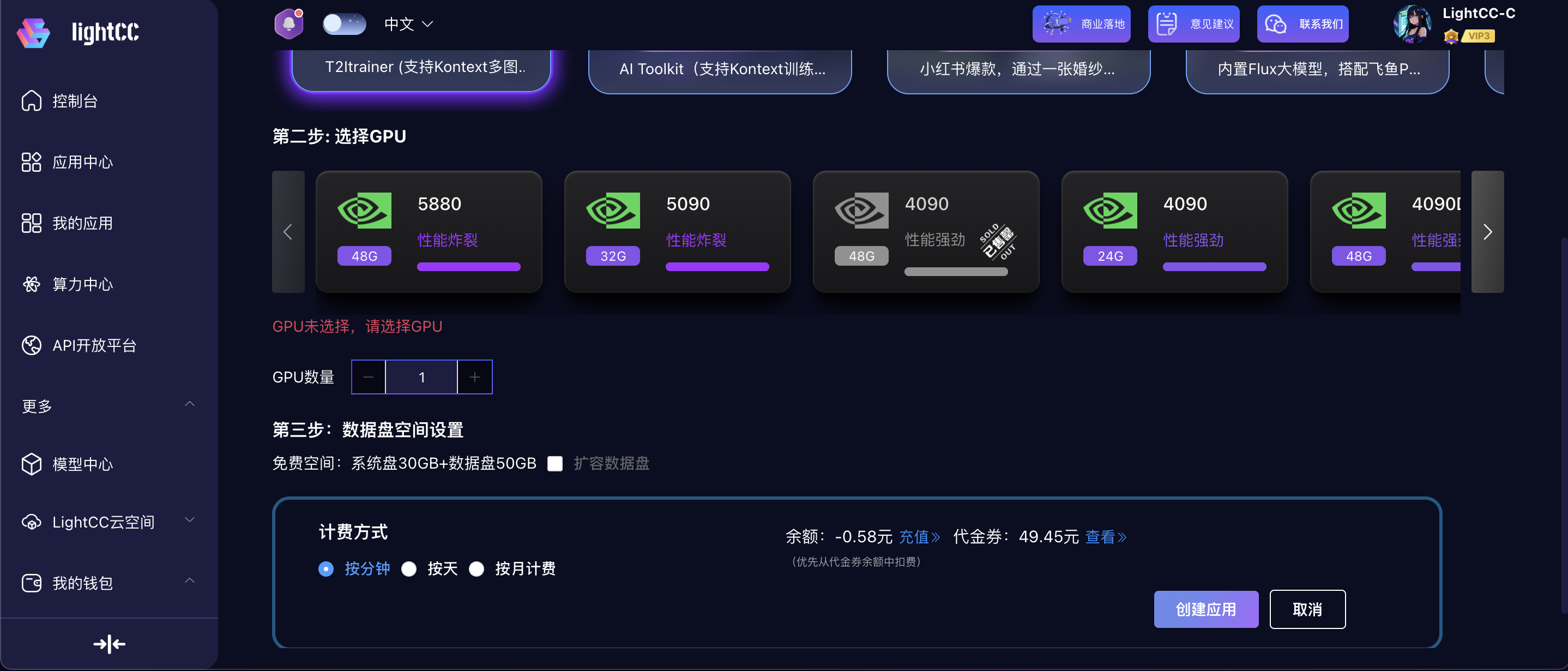
创建应用
成功创建后,页面会自动跳转至【我的应用】,新建应用会显示“创建中”状态
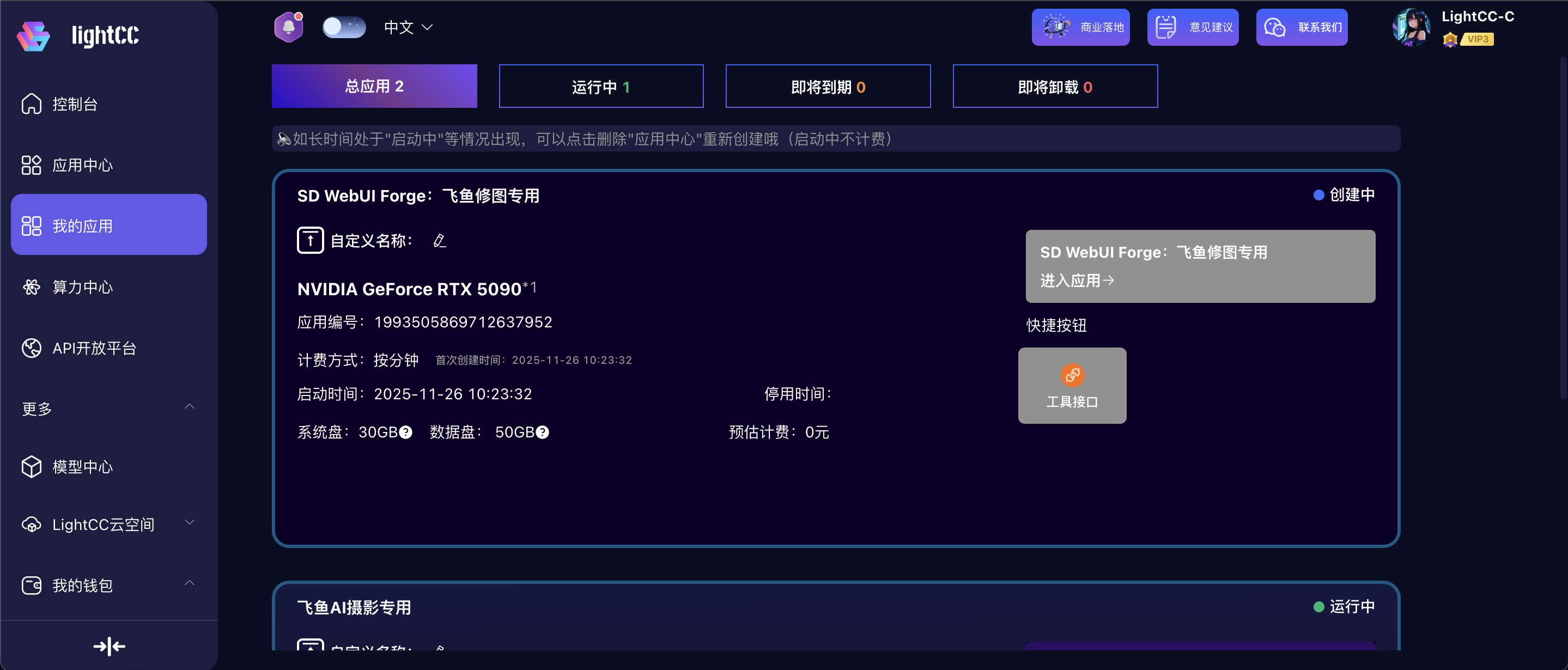
创建完成
稍等片刻,待状态转为“运行中”,点击【进入应用】,即可使用应用
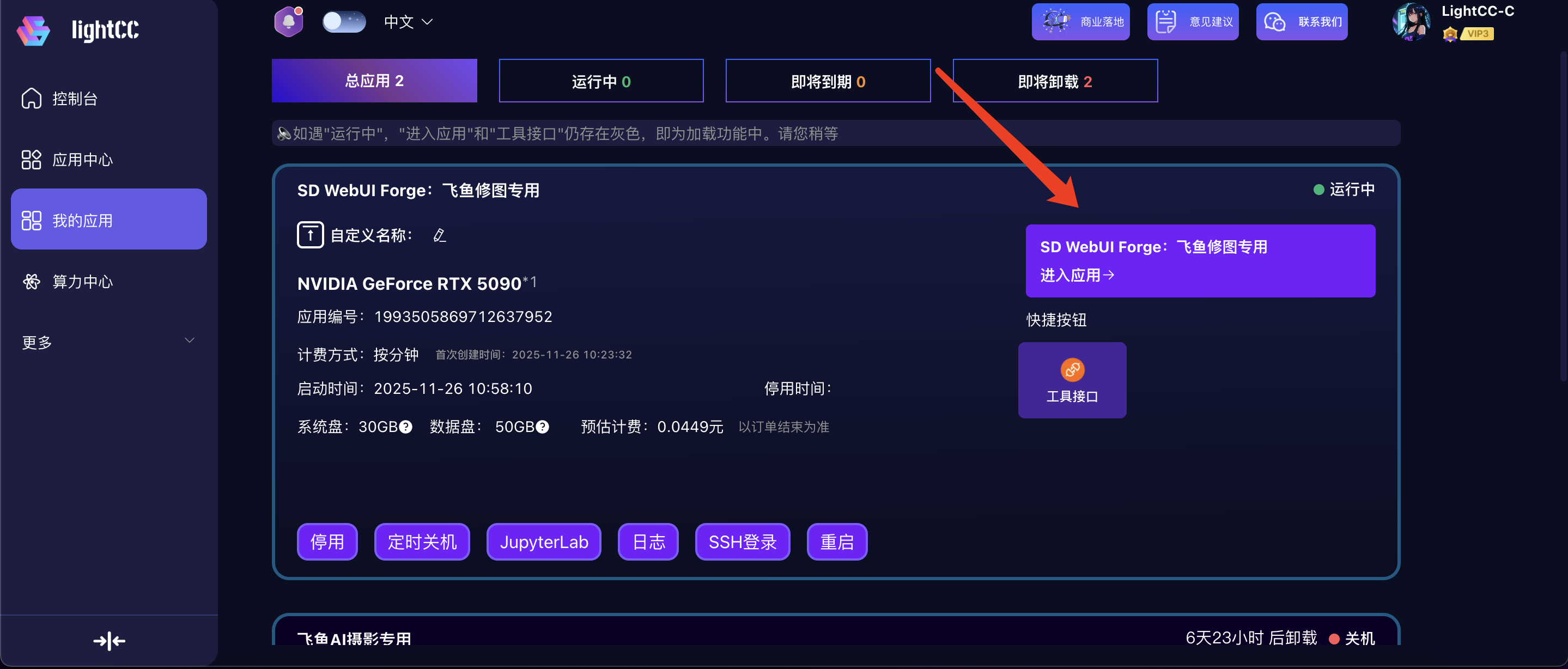
使用应用
进入应用
应用排队:完成"创建应用"后,会在应用卡片中出现“创建中”的字样,此时为应用排队,稍等1-2 分钟即可,排队等待的时间不会计算消耗。
应用启动:当应用卡片中“创建中”的字样变成“运行中”,即完成排队,可点击“进入应用”开始作业,此时开始计算消耗。
关于“停用”:如果你在创建完成应用后,点击“停用”,直至应用状态为“已关机”,则为停用成功,停止计费。
提示:目前有 7 天免费保存,存储暂绑定GPU,所以重新开机时会有占用等情况。
应用具体的工作页面,以Stable Diffusion 为例,按网络教程调整相关参数,即可开始创作。
重要提示:
- 请勿生成违禁图片,严禁挖矿,否则法律后果自负,一经发现立即封号!
- 使用过程中,如果出现连续生图失败,可能是由爆显存导致,可重启 WebUI 解决该问题。
应用编号
1.可用于向运营同学提交问题时的依据
2.复制“应用编号”:可在我的应用页面,应用卡片上直接复制相关应用的编号。
配置存储
- 应用停用后,相关配置的免费存储时间为 7天,保存期间可以选择重新开机。
- 时长计算:若 7天内“重新开机”成功,再次停用,则仍然会有7 天的免费存储,依次类推。
- 特别说明:目前存储是和GPU绑定的,因为存储是免费的,所以重新开机的时候有被占用的情况。
- 目前解决方式:
- 等待占用人停用,或者重新创建应用
- 如果需求量大的话,可以考虑通过包周、包月、包年避免期间占用
- 目前解决方式:
重新开机
- 应用停用后 7天内,可点击应用卡片上的“重新开机”,找回相关的历史配置。
- 应用卡片右上角的“倒计时”为该应用剩余的免费存储时长,若提示“已释放”则该应用的存储已过期被清理。
查看日志
控制台日志查看路径:应用卡片上点击【查看日志】即可
文件管理
登录【文件管理】
- 功能说明:可使用“文件管理”功能上传和管理模型和插件
- 使用方法:登录LightCC【我的应用】,创建应用后,点击应用右侧工具栏中的【文件管理】按钮,进入文件管理页面
- 根据不同应用类型的适配,详细列出具体应用需要的模型快捷目录,可点击目录快捷跳转至模型路径
使用【文件管理】
首次进入文件管理页面,展示为我的文件(根目录下的所有文件/文件夹)
点击左侧导航栏中的快捷访问_数据盘,进入数据盘目录下进行上传模型/插件
- embedding(嵌入式模型目录)
- extensions(插件目录)
- models(Stable-diffusion、Lora、VAE、hypernetworks)
- outputs(图片输出目录)

上传个lora模型为例,进入models_Lora目录中,把本机文件直接拖进目录里

底部可查看进度或者取消上传

- 如何进行压缩/解压文件
压缩是包含在下载动作中,举例下载outputs文件夹
如何设置/取消快捷访问
以Stable-diffusion模型目录举例,进入model中,选择Stable-diffusion模型文件夹,点击右上角创建快捷访问的按钮,可创建多个快捷访问方式
如果取消可点击减号图标
模型上传
模型上传方式:
1.从文件管理中拖入
2.从LightCC云存储下载至目录
如何选择GPU
NVIDIA显卡产品线
NVIDIA常见的三大产品线如下:
Quadro类型: Quadro系列显卡一般用于特定行业,比如设计、建筑等,图像处理专业显卡,比如CAD、Maya等软件。
GeForce类型: 这个系列显卡官方定位是消费级,常用来打游戏。但是它在深度学习上的表现也非常不错,很多人用来做推理、训练,单张卡的性能跟深度学习专业卡Tesla系列比起来其实差不太多,但是性价比却高很多。
Tesla类型: Tesla系列显卡定位并行计算,一般用于数据中心,具体点,比如用于深度学习,做训练、推理等。Tesla系列显卡针对GPU集群做了优化,像那种4卡、8卡、甚至16卡服务器,Tesla多块显卡合起来的性能不会受>很大影响,但是Geforce这种游戏卡性能损失严重,这也是Tesla主推并行计算的优势之一。
Quadro类型分为如下几个常见系列:
NVIDIA RTX Series系列: RTX A2000、RTX A4000、RTX A4500、RTX A5000、RTX A6000
Quadro RTX Series系列: RTX 3000、RTX 4000、RTX 5000、RTX 6000、RTX 8000
GeForce类型分为如下几个常见系列:
Geforce 20系列:RTX 2060、RTX 2060 Super、RTX 2070、RTX 2070 Super、RTX 2080、RTX 2080 Super、RTX 2080Ti
Geforce 30系列: RTX 3050、RTX 3060、RTX 3060Ti、RTX 3070、RTX 3070Ti、RTX 3080、RTX 3080Ti、RTX 3090 RTX 3090Ti
Geforce 40系列: RTX 4060、RTX 4060Ti、RTX 4070、RTX 4070s、RTX 4090、RTX 4090D
Tesla类型分为如下几个常见系列:
A-Series系列: A10、A16、A30、A40、A100
T-Series系列: T4
V-Series系列: V100
P-Series系列: P4、P6、P40、P100
K-Series系列: K8、K10、K20c、K20s、K20m、K20Xm、K40t、K40st、K40s、K40m、K40c、K520、K80
GPU信息
| 型号 | 显存 | 半精度(TFLOPS) | 单精度(TFLOPS) | 双精度(TFLOPS) | CUDA核心数量 | Tensor核心数量 | 架构 | 显存类型 |
|---|---|---|---|---|---|---|---|---|
| NVIDIA RTX A5000 | 24GB | 55.50 | 27.77 | 0.867 | 8192 | 256 | Ampere | GDDR6 |
| Quadro RTX 5000 | 16GB | 22.30 | 11.15 | 0.348 | 3072 | 384 | Turing | GDDR6 |
| GeForce 3090Ti | 24GB | 80 | 40.0 | 0.627 | 10752 | 336 | Ampere | GDDR6X |
| GeForce 3090 | 24GB | 71 | 35.58 | 0.558 | 10496 | 328 | Ampere | GDDR6X |
| GeForce 3080Ti | 12GB | 68.5 | 34.71 | 0.533 | 10240 | 320 | Ampere | GDDR6X |
| GeForce 3080 | 12GB | 58.9 | 29.77 | 0.465 | 8704 | 272 | Ampere | GDDR6X |
| GeForce 3070 | 8GB | 40.6 | 20.31 | 0.318 | 5888 | 184 | Ampere | GDDR6X |
| GeForce 3060Ti | 8GB | 33.4 | 16.20 | 0.253 | 4864 | 152 | Ampere | GDDR6 |
| GeForce 3060 | 12GB | 25.5 | 12.74 | 0.199 | 3584 | 112 | Ampere | GDDR6 |
| GeForce 2080Ti | 11GB | 26.9 | 13.4 | 0.42 | 4352 | 544 | Turing | GDDR6 |
| Tesla V100 NVLink | 32GB | 31.33 | 15.7 | 7.8 | 5120 | 640 | Volta | HBM2 |
| Tesla V100 NVLink | 16GB | 31.33 | 15.7 | 7.8 | 5120 | 640 | Volta | HBM2 |
| Tesla V100S PCIE | 32GB | 32.71 | 16.4 | 8.2 | 5120 | 640 | Volta | HBM2 |
| Tesla P100 PCIE | 16GB | 21.22 | 10.6 | 5.3 | 3584 | 无 | Pascal | HBM2 |
| Tesla T4 | 16GB | 16.30 | 8.141 | 0.254 | 2560 | 320 | Turing | GDDR6 |
| GeForce ITAN X | 12GB | 13.28 | 6.691 | 0.153 | 3072 | 无 | Maxwell | GDDR5 |
性能选卡
半精度排序
| 型号 | 显存 | 半精度(TFLOPS) |
|---|---|---|
| GeForce RTX 3090Ti | 24GB | 80 |
| GeForce RTX 3090 | 24GB | 71 |
| GeForce RTX 3080Ti | 12GB | 68.5 |
| GeForce RTX 3080 | 12GB | 58.9 |
| NVIDIA RTX A5000 | 24GB | 55.50 |
| GeForce RTX 3070 | 8GB | 40.6 |
| GeForce RTX 3060Ti | 8GB | 33.4 |
| Tesla V100S PCIE | 32GB | 32.71 |
| Tesla V100 NVLink | 32GB | 31.33 |
| Tesla V100 NVLink | 16GB | 31.33 |
| GeForce RTX 3060 | 12GB | 25.5 |
| GeForce RTX 2080Ti | 11GB | 26.9 |
| Quadro RTX 5000 | 16GB | 22.30 |
| Tesla P100 PCIE | 16GB | 21.22 |
| Tesla T4 | 16GB | 16.30 |
| GeForce GTX TITAN X | 12GB | 13.28 |
选择GPU参数
显卡性能主要根据如下几个参数来判断:
- 显存: 显存即显卡内存,显存主要用于存放数据模型,决定了我们一次读入显卡进行运算的数据多少(batch size)和我们能够搭建的模型大小(网络层数、单元数),是对深度学习研究人员来说很重要的指标,简述来讲,显存越大越好。
- 架构:在显卡流处理器、核心频率等条件相同的情况下,不同款的GPU可能采用不同设计架构,不同的设计架构间的性能差距还是不小的,显卡架构性能排序为:Ampere > Turing > Volta > Pascal > Maxwell > Kepler > Fermi > Tesla
- CUDA核心数量:CUDA是NVIDIA推出的统一计算架构,NVIDIA几乎每款GPU都有CUDA核心,CUDA核心是每一个GPU始终执行一次值乘法运算,一般来说,同等计算架构下,CUDA核心数越高,计算能力会递增。
- Tensor(张量)核心数量:Tensor 核心是专为执行张量或矩阵运算而设计的专用执行单元,而这些运算正是深度学习所采用的核心计算函数,它能够大幅加速处于深度学习神经网络训练和推理运算核心的矩阵计算。Tensor Core使用的计算能力要比Cuda Core高得多,这就是为什么Tensor Core能加速处于深度学习神经网络训练和推理运算核心的矩阵计算,能够在维持超低精度损失的同时大幅加速推理吞吐效率。
- 半精度:如果对运算的精度要求不高,那么就可以尝试使用半精度浮点数进行运算。这个时候,Tensor核心就派上了用场。Tensor Core专门执行矩阵数学运算,适用于深度学习和某些类型的HPC。Tensor Core执行融合乘法加法,其中两个44 FP16矩阵相乘,然后将结果添加到44 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵。NVIDIA将Tensor Core进行的这种运算称为混合精度数学,因为输入矩阵的精度为半精度,但乘积可以达到完全精度。Tensor Core所做的这种运算在深度学习训练和推理中很常见。
- 单精度: Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
- 双精度:双精度适合要求非常高的专业人士,例如医学图像,CAD。
具体的显卡使用需求,还要根据使用显卡处理的任务内容进行选择合适的卡,除了显卡性能外,还要考虑CPU、内存以及磁盘性能,关于GPU、CPU、内存、磁盘IO性能。
对于不同类型的神经网络,主要参考的指标是不太一样的。下面给出一种指标顺序的参考:
卷积网络和Transformer:Tensor核心数>单精度浮点性能>显存带宽>半精度浮点性能
循环神经网络:显存带宽>半精度浮点性能>Tensor核心数>单精度浮点性能
选择内存
内存应当选择采用时序频率高以及容量大的内存,虽然机器学习的性能和内存大小无关,但是为了避免GPU执行代码在执行时被交换到磁盘,需要配置足够的RAM,也就是GPU显存对等大小内存。
例如使用24G内存的Titan RTX,至少需要配置24G内存,不过,如果使用更多GPU并不需要更多内存。如果内存大小已经匹配上GPU卡的显存大小,仍然可能在处理极大的数据集出现内存不足的情况,这个时候应该升配GPU来获得比当 前双倍的内存或者更换内存更大实例。
因为内存在充足的情况下不会影响性能,如果内存使用超载则会导致进程被Killd或者程序运行缓慢情况。
选择CPU参数
在load数据过程中,就需要用到大量的CPU和内存,如果CPU主频较低或者CPU核心较少的情况下,会限制数据的读取速度,从而拉低整体训练速度,成为训练中的瓶颈。
建议选择核心较多且主频较高的的机器,每台机器中所分配的CPU核心数量可以通过创建页面查看,也可以通过CPU型号去搜索该CPU的主频和睿频的大小。
CPU的核心数量也关系到num_workers参数设置的数值,num_worker设置得大,好处是寻batch速度快,因为下一轮迭代的batch很可能在上一轮/上上一轮…迭代时已经加载好了。坏处是内存开销大,也加重了CPU负担(worker加载数据到RAM的进程是CPU进行复制)。num_workers的经验设置值是 <= 服务器的CPU核心数。
选择磁盘
在进行训练或者推理的过程中需要不断的与磁盘进行交互,如果磁盘IO性能较差,则同样会成为整个训练速度的瓶颈;恒源云一直推荐用户使用 /hy-tmp目录进行数据集存储和训练,因为该目录为机器本地磁盘,训练速度最快,IO效率最高。
平台的所有机器中,目前大多数机器都采用SSD高效磁盘,比传统机械磁盘速度要高几倍,还有速度更快的NVME磁盘,在进行机器选择的时可根据需要选择磁盘IO较好的磁盘。
平台中各种类型磁盘读写效率如下:
以下内容均测试为随机读/写性能,这也是磁盘在日常的使用场景,磁盘厂商所描述的3000MB+、5000MB+这种磁盘读写效率均为顺序读写,并不符合我们日常使用场景。
NVME类型磁盘: 每秒随机写 >= 1700MB 每秒随机读 >= 2400MB
SSD类型磁盘: 每秒随机写 >= 460MB 每秒随机读 >= 500MB
HDD类型磁盘: 每秒随机写 ~= 200MB 每秒随机读 ~= 200MB